![]()
|
|
|
|
|---|
[Meßbedingungen] - [Durchführung] - [Laufzeiten] - [Graphiken] - [Detaillierte Resultate] - [Bemerkungen]
![]()
Datum: 08-10/02/2001, 24/03/2001
Ausgeführt von: Jasper Möller, moellerj@fmi.uni-konstanz.de
Betriebssystem: Linux 2.2.18
CPU: AMD Athlon, 800MHz
Speicher: 256MB
JDK: 1.3.0, IBM
Javaopt: -Xmx180M
Javacopt: -O
Datendatei: 16s-rRNA-schnitt.FASTA (2000 Sequenzen mit max. 80 Zeichen)
Anfragedatei: 16s-rRNA-schnitt-ref.FASTA (20 Sequenzen)
Für jedes Paar von Vergleichs- und Meßsequenz wurde die Systemzeit (bestimmt mit System.currentTimeMillis()) direkt vor Aufruf von rRNA.getDistance() und direkt danach bestimmt und die Differenz für alle Anfragen addiert:
public static void main(...)
{
...
long duration = 0;
long start = 0;
long stop = 0;
...
while(true)
//break, falls keine weitere Vergleichssubstanz
{
while(true)
//break, falls keine weitere Substanz mehr vorhanden
...
start = System.currentTimeMillis();
distance = getDistance(...);
stop = System.currentTimeMillis();
duration += stop - begin;
...
}
//Alle Anfragen abgearbeitet
}
Dabei ist zu beachten, daß in der Methode getDistance() nicht nur die Laufzeit des Dijkstra-Algorithmus eingeht, sondern auch noch die zum Aufbau des Graphen benötigte Zeit. Dieser Anteil sollte aber idealerweise für jede Queue konstant bleiben.
Für jede normale PriorityQueue wurde dieser Vorgang automatisiert viermal, bei den BucketQueues zweimal, wiederholt und die Ergebnisse gesammelt.
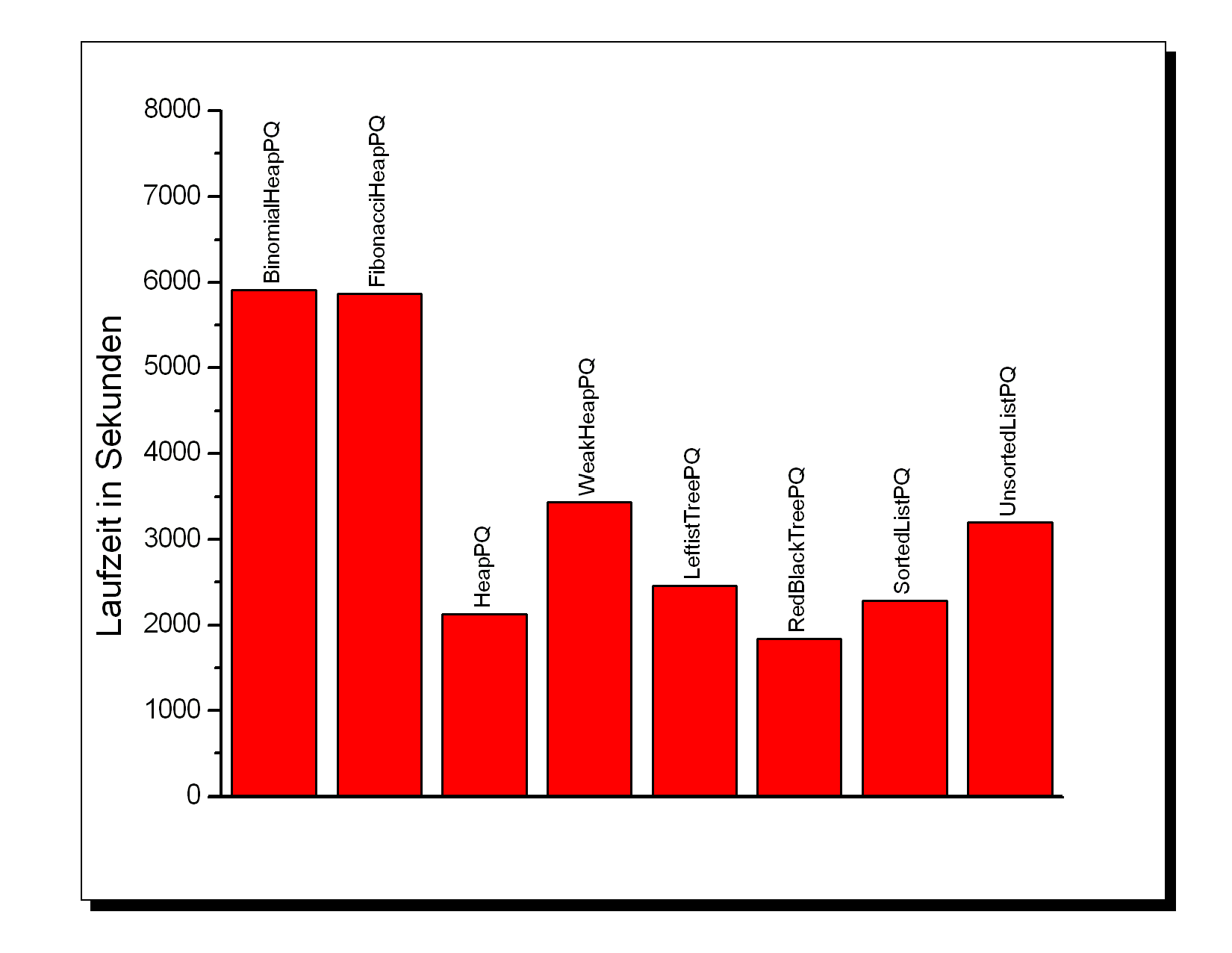
|
Queue |
BinomialHeapPQ |
FibonacciHeapPQ |
HeapPQ (d=2) |
WeakHeapPQ |
|---|---|---|---|---|
|
Laufzeit (s) |
5911,68 |
5865,67 |
2133,72 |
3440,87 |
|
Queue |
LeftistTreePQ |
RedBlackTreePQ |
SortedListPQ |
UnsortedListPQ |
RedBlackTreeBucketPQ *) |
|---|---|---|---|---|---|
|
Laufzeit (s) |
2460,84 |
1841,84 |
2285,18 |
3200,23 |
1842,08 **) |
*) Da die Ergebnisse der Bucketqueues nur minimal von denen der normalen Queues abweichen, ist hier nur die Bucketqueue mit den besten Einzelkomponenten aufgeführt.
**) Mittelwert nur aus zwei Messungen
Detaillierte Resultate im Archiv: rRNA-Results.tar.gz
Im wesentlichen gelten auch hier die Resultate, die für die Fahrplanapplikation festgestellt wurden: Die hochoptimierten PriorityQueues können ihren theoretischen Performancevorteil nicht ausspielen. Insbesondere BinomialHeapPQ und FibonacciHeapPQ schneiden beide sehr schlecht ab, was aber wieder zum Teil an der Implementation durch Vectors liegen könnte, wogegen die restlichen Strukturen direkt verzeigert aufgebaut sind. Interessant auch hier das besonders gute Abschneiden der relativ primitiven SortedListPQ. Insgesamt werden die Unterschiede zwischen den Queues durch den Aufbau der Messung etwas nivelliert, da hierbei die Zeiten zum Einlesen der Sequenzen und zum Aufbau des Graphen mit eingehen. Diese Zeiten sollten für jede Messung aber einigermassen konstant bleiben.
![]()
|
|
|
|
|---|
[Meßbedingungen] - [Durchführung] - [Laufzeiten] - [Graphiken] - [Detaillierte Resultate] - [Bemerkungen]